Sistemas de recuperación
Introducción
Es normal enfrentarse a situaciones en las que se produce un fallo y cuando se produce, hay que mantener las propiedades ACID aunque se produzca un fallo en la base de datos.
El esquema de recuperación de la base de datos es el encargado de asegurar ante posibles fallos:
La consistencia.
La disponibilidad.
El tiempo de pérdida de servicio.
El tiempo de recuperación ante un fallo debe ser mínimo.
Clasificación de fallos
Fallo en la transacción: En una transacción abortada pueden producirse fallos por diferentes motivos:
Error lógico: Puede existir una restricción lógica en el sistema que evite que esa transacción se ejecute correctamente. Por ejemplo, una entrada incorrecta.
Error del sistema: Cuando es sistema se encuentra en un estado inconsistente, por ejemplo los procesos bloqueados por una mala solución en concurrencia.
Caída del sistema. Este error se debe normalmente a un mal funcionamiento de un dispositivo hardware (o corte de suministro eléctrico). Como consecuencia la máquina se apaga y se pierde la memoria no permanente. La transacción en ejecución no debe continuar. Los soportes de memoria permanente (discos) no se ven afectados.
Fallo de disco. Debido a un fallo hardware la información se corrompe y es necesario ejecutar procesos de recuperación de información a través de los backups existentes.
Dependiendo del tipo de fallo se selecciona una forma de recuperación que usan diferentes tipos de algoritmos. Estos algoritmos constan de dos partes:
Tareas de preparación ante posibles fallos: Son aquellas que se ejecutan durante el funcionamiento normal del sistema con el fin de asegurar que, si se produce un fallo, este se pueda recuperar. (Backups).
Acciones posteriores a un fallo: Se encargan de comprobar la consistencia de la base de datos y asegurar las propiedades ACID.
Estructuras de almacenamiento
Volátil: comprende la información que desaparece cuando un sistema informático pierde la alimentación eléctrica.
Permanente o no volátil: es aquella almacenada en cualquier medio de almacenamiento (discos duros, USB...).
Arquitecturas de recuperación
Sin réplicas ni varias zonas de disponibilidad
Es una arquitectura simple donde el sistema se conecta a la base de datos en una única ubicación concreta.
Es una arquitectura poco deseable por lo vulnerable que es.
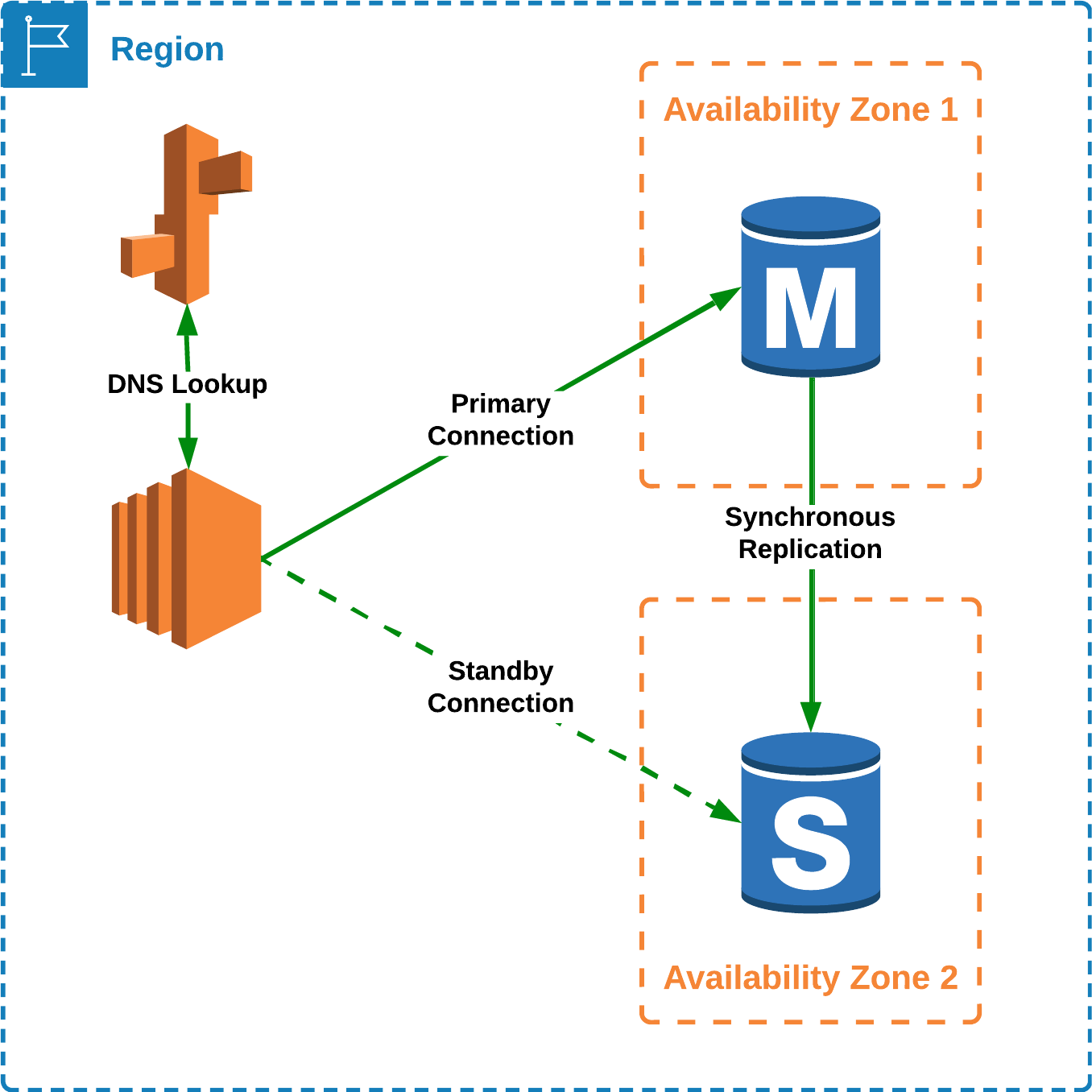
Con una réplica en standby de la base de datos en varias zonas de disponibilidad
En esta arquitectura una base de datos se encuentra en una zona de disponibilidad y la replica se mantiene en standby en otra zona de disponibilidad, con lo que si ocurriera un error en nuestra base de datos principal, automáticamente entraría en servicio la réplica.
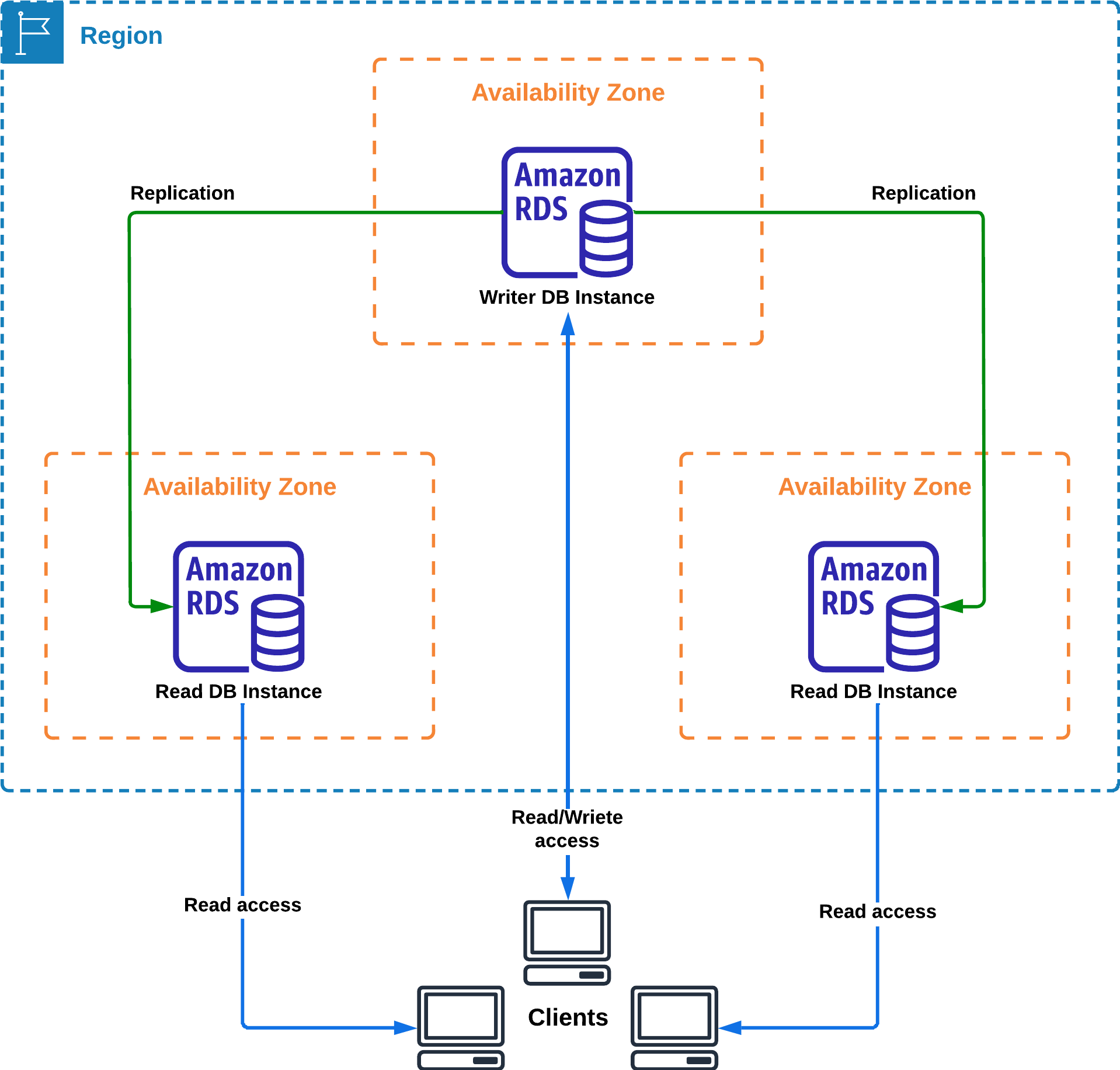
Con una réplica en standby de la base de datos y otra replica para las consultas de lectura en diferentes zonas de disponibilidad
Esta arquitectura tiene una instancia primaria de la base de datos se encuentra en una zona de disponibilidad, otra réplica que se mantiene en standby en otra zona de disponibilidad y otra réplica en otra zona de disponibilidad para las consultas de lectura.
Esto nos aporta una alta disponibilidad y la posibilidad de recuperación.
Recuperación y atomicidad
Si se produce un error durante la ejecución de una transacción, no sabremos si esta se ha ejecutado correctamente o no. Teniendo en mente este hecho podremos:
Volver a ejecutar la transacción: Se asume que no ha tenido efecto en la base de datos.
No volver a ejecutar la transacción: Se asume que se ha ejecutado correctamente.
Independientemente de la opción escogida, nuestra base de datos se quedará en un estado inconsistente.
Esta situación se produce por no tener certeza sobre si la transacción ha finalizado correctamente o no.
Recuperación basada en registro histórico (redo logs)
Todas las bases de datos relacionales tienen un registro histórico, que es donde se almacenan todas las modificaciones realizadas en la base de datos.
Estructura del registro histórico:
Identificador de transacción.
Identificador del elemento de datos: Hace referencia del dato que se modifica que normalmente coincide con la ubicación del elemento en disco.
Valor anterior.
Valor nuevo.
Al realizar una escritura es necesario crear el registro histórico antes de modificar nada en la base de datos.
Una vez que se crea el registro histórico se procede a modificar la base de datos.
Gracias a este comportamiento se pueden realizar operaciones de deshacer para volver a valores anteriores.
Alta disponibilidad en bases de datos
La alta disponibilidad es la cualidad de un sistema que asegura un alto nivel de rendimiento operativo durante un periodo de tiempo determinado.
Funciona como un mecanismo de respuesta a fallos de infraestructura.
Mecanismos de redundancia (si uno falla entra el otro).
Facilitar las tareas de mantenimiento o actualización.